Когда мы говорим о современных языковых моделях, одна из главных «суперсил» — способность удерживать в памяти огромные объёмы текста.
Claude от Anthropic известен своим внушительным контекстным окном, но как именно он это делает?
В этой статье мы разберём архитектурные решения, механизмы внимания и оптимизации, которые позволяют Claude эффективно обрабатывать длинные тексты — от научных статей до целых книг.
Вы узнаете, какие технические приёмы лежат в основе, с какими ограничениями сталкиваются разработчики и как использовать эти знания на практике.
Введение: Проблема длинных контекстов в современных LLM
Обработка длинных последовательностей — одна из самых сложных задач для языковых моделей.
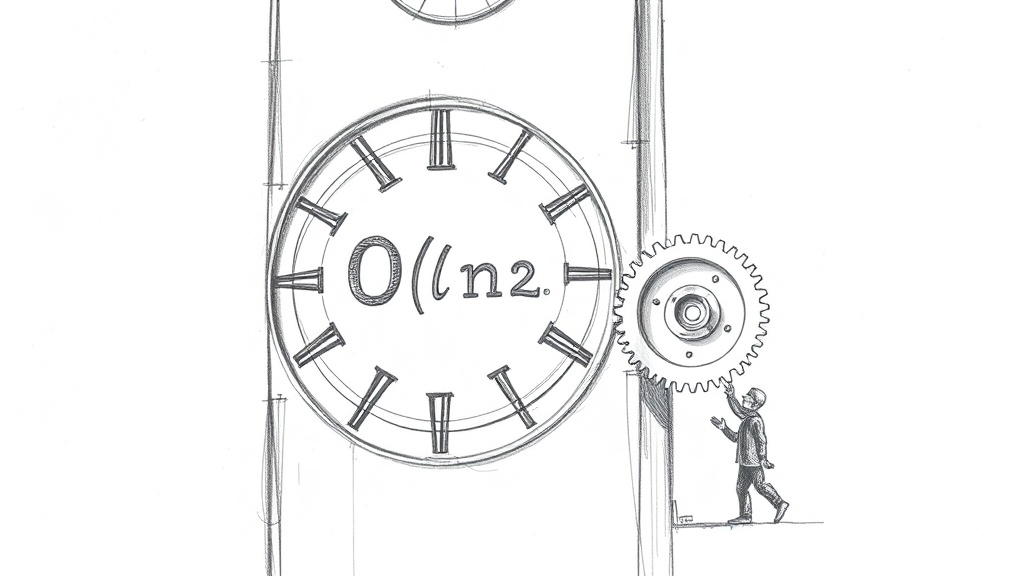
Стандартный механизм внимания в трансформерах имеет квадратичную сложность: для последовательности из n токенов требуется O(n²) операций.
Это означает, что при увеличении длины текста в два раза вычислительные затраты растут в четыре раза.
Для контекстов в десятки и сотни тысяч токенов такой подход становится непрактичным.
Кроме того, растёт потребление памяти: каждый токен «смотрит» на все предыдущие, и для хранения промежуточных результатов (матриц внимания) требуются гигабайты VRAM.
Именно поэтому ранние модели, такие как GPT-2, были ограничены контекстом в 1024 токена. Современные решения, включая Claude, используют комбинацию архитектурных модификаций, чтобы преодолеть это ограничение.
Важно: Понимание квадратичной сложности — основа для осознания инноваций Claude. Без специальных техник обработка длинных текстов была бы невозможна.
Квадратичная сложность внимания
Стандартное внимание (scaled dot-product attention) вычисляется по формуле: Attention(Q,K,V) = softmax(QK^T / sqrt(d)) V.
Здесь Q, K, V — матрицы запросов, ключей и значений. Умножение Q на K^T даёт матрицу размером n×n, что и приводит к квадратичной сложности.
Формула внимания
Каждый токен взаимодействует со всеми остальными, что даёт модели богатое представление контекста, но ценой огромных вычислительных ресурсов.
Для последовательности из 100 000 токенов матрица внимания занимает около 40 ГБ в памяти (при float16), что превышает возможности даже современных GPU.
Проблема памяти и вычислений
Помимо памяти, квадратичная сложность замедляет как обучение, так и инференс.
При генерации каждого нового токена модель должна пересчитывать внимание для всей последовательности, что делает процесс медленным.
Именно поэтому исследователи ищут способы аппроксимировать или упростить внимание, сохраняя при этом качество.
Почему длинный контекст важен

Возможность обрабатывать длинные тексты открывает множество практических сценариев. Вот лишь несколько примеров:
- Анализ книг и отчётов: Модель может прочитать целую книгу и ответить на вопросы по её содержанию, не требуя разбиения на части.
- Обработка диалогов: В чат-ботах длинная история разговора позволяет сохранять контекст на протяжении сотен сообщений.
- Извлечение информации из больших данных: Юридические документы, научные статьи, медицинские записи — всё это требует понимания множества страниц текста.
Совет: Если вы работаете с длинными документами, попробуйте явно указывать в запросе, на каких разделах нужно сосредоточиться — это повышает точность ответов.
Архитектурные решения Claude для работы с длинными текстами
Claude использует комбинацию нескольких техник, а не одно решение. Это позволяет достичь баланса между качеством, скоростью и потреблением ресурсов. Рассмотрим ключевые архитектурные особенности.
Механизм разреженного внимания (Sparse Attention)
Вместо того чтобы вычислять внимание между всеми парами токенов, разреженное внимание позволяет модели фокусироваться только на релевантных частях контекста. Это снижает сложность с O(n²) до O(n log n) или даже O(n).
Глобальное vs локальное внимание
В разреженных механизмах часть токенов (например, специальные [CLS] токены) имеют глобальное внимание — они видят всю последовательность.
Остальные токены взаимодействуют только с локальным окном. Такой подход напоминает работу Longformer или BigBird, где каждый токен «смотрит» на соседей и на несколько глобальных токенов.
Паттерны разреженности
Паттерны могут быть фиксированными (например, окно фиксированной ширины) или динамическими, когда модель сама решает, на какие токены обратить внимание.
В Claude, по опыту специалистов, используются фиксированные паттерны с возможностью адаптации через механизмы памяти.
Примеры реализации
В индустрии известны реализации Sparse Attention от OpenAI (в моделях GPT-3) и Google (в BigBird).
Claude, вероятно, использует схожие принципы, но с собственными оптимизациями, учитывающими специфику обучения.
Скользящее окно внимания (Sliding Window Attention)
Это частный случай разреженного внимания, где каждый токен взаимодействует только с токенами в окне фиксированной ширины w.
Сложность становится O(n·w), что линейно по длине последовательности, если w — константа.
Размер окна
Размер окна — гиперпараметр, который влияет на способность модели улавливать долгосрочные зависимости.
В Claude окно, как правило, достаточно велико (несколько тысяч токенов), чтобы охватить абзацы и разделы текста.
Перекрытие окон
Чтобы избежать разрывов в контексте, окна могут перекрываться. Это позволяет модели «видеть» информацию на границах сегментов.
Например, если окно размером 4096 токенов сдвигается на 2048 токенов, каждое следующее окно включает половину предыдущего.
Влияние на качество
Скользящее окно хорошо работает для задач, где важна локальная связность (например, генерация текста), но может ухудшать понимание глобального контекста.
Claude компенсирует это дополнительными механизмами, такими как рекуррентные блоки.
Рекуррентные блоки и сжатие контекста

Для сохранения информации из предыдущих сегментов Claude использует рекуррентные или компрессионные методы.
Это напоминает архитектуру рекуррентных трансформеров, где состояние модели передаётся между сегментами.
Компрессия памяти
Один из подходов — сжатие ключей и значений из предыдущих сегментов в компактное представление.
Например, модель может агрегировать информацию из окна в несколько «памятных» токенов, которые затем используются при обработке следующего окна.
Рекуррентные трансформеры
В рекуррентных трансформерах (например, Transformer-XL) состояние скрытого слоя передаётся от одного сегмента к другому.
Это позволяет модели «помнить» информацию на протяжении тысяч токенов без квадратичного роста сложности.
Интеграция с вниманием
В Claude рекуррентные блоки, вероятно, интегрированы с механизмом внимания: модель может обращаться как к текущему окну, так и к сжатому представлению предыдущих сегментов.
Это даёт баланс между локальной точностью и глобальным контекстом.
Важно: Claude использует комбинацию нескольких техник, а не одно решение. Это позволяет достичь синергии: разреженное внимание снижает сложность, а рекуррентные блоки сохраняют долгосрочные зависимости.
Позиционное кодирование и его роль в длинных контекстах
Позиционное кодирование критически важно для длинных контекстов.
Стандартные синусоидальные кодировки, используемые в оригинальном трансформере, плохо обобщаются на длины, превышающие те, что были в обучающих данных. Claude применяет более продвинутые методы.
Относительное позиционное кодирование
Вместо абсолютных позиций (токен №1, №2 и т.д.) модель использует относительные расстояния между токенами. Это позволяет ей лучше обобщать на последовательности произвольной длины.
Преимущества относительного кодирования
- Инвариантность к длине: Модель не «заучивает» конкретные позиции, а учится работать с отношениями между токенами.
- Лучшее обобщение: Если модель обучена на текстах длиной до 32K токенов, она может работать с контекстом в 100K токенов без значительной потери качества.
Реализация в Claude
Anthropic не раскрывает точных деталей, но по косвенным данным (например, из патентов и публикаций) можно предположить, что Claude использует вариацию относительного кодирования, возможно, с дополнительными адаптивными весами.
Позиционное кодирование на основе вращений (RoPE)
RoPE (Rotary Position Embedding) — популярный метод, который применяется в многих современных моделях, включая Llama и, вероятно, Claude.
Он кодирует позиции через вращение векторов запросов и ключей в многомерном пространстве.
Принцип работы RoPE
Для каждой пары токенов с позициями i и j вычисляется матрица вращения, которая зависит от разности i — j.
Это позволяет модели учитывать относительные расстояния без дополнительных параметров.
RoPE естественным образом обобщается на длинные последовательности, так как вращения периодичны.
Преимущества для длинных последовательностей
RoPE не требует обучения дополнительных весов для позиций, что делает его эффективным для контекстов любой длины.
Кроме того, он хорошо сочетается с разреженным вниманием, так как не зависит от абсолютных позиций.
Управление памятью и кэширование в Claude
Эффективное управление памятью — ключ к обработке контекстов длиной в сотни тысяч токенов.
Даже с разреженным вниманием, хранение промежуточных результатов может быть проблемой.
Кэш ключей-значений (KV Cache)
Во время инференса модель сохраняет вычисленные ключи и значения для каждого слоя, чтобы не пересчитывать их при генерации каждого нового токена.
Это стандартная практика, но для длинных контекстов KV cache может занимать десятки гигабайт.
Принцип работы KV cache
При генерации токена модель вычисляет запрос для текущего токена и использует сохранённые ключи и значения из предыдущих шагов.
Это ускоряет инференс, но требует памяти для хранения всех ключей и значений для каждого слоя и каждой головы внимания.
Проблемы с памятью при больших контекстах
Для контекста в 100K токенов, модели с 32 слоями и 32 головами внимания, KV cache может занимать более 50 ГБ в памяти (при float16).
Это превышает объём VRAM большинства consumer GPU, поэтому требуются методы сжатия.
Сжатие KV cache

Claude, вероятно, использует несколько техник для уменьшения размера KV cache:
- Прореживание кэша: Удаление ключей и значений для токенов, которые считаются менее важными (например, на основе весов внимания).
- Квантование: Хранение ключей и значений в формате с меньшей точностью (например, int8 вместо float16), что снижает потребление памяти в два раза.
- Адаптивное сжатие: Динамическое изменение степени сжатия в зависимости от загрузки памяти.
Совет: При работе с очень длинными текстами (более 50K токенов) старайтесь минимизировать количество параллельных запросов к API, чтобы избежать нехватки памяти на сервере.
Оптимизация инференса для длинных последовательностей
FlashAttention — одна из ключевых оптимизаций, позволяющая обрабатывать длинные контексты без взрывного роста времени.
Она была разработана в Стэнфорде и широко применяется в современных моделях.
FlashAttention и его реализация
FlashAttention уменьшает использование памяти и ускоряет вычисления за счёт тайлинга и пересчёта.
Вместо того чтобы хранить всю матрицу внимания в памяти, она разбивается на блоки (тайлы), которые обрабатываются последовательно.
Тайлинг
Матрица QK^T разбивается на блоки размером, например, 128×128. Каждый блок вычисляется отдельно, и результат агрегируется.
Это позволяет уложиться в быструю память (SRAM) GPU, избегая медленных операций с глобальной памятью.
Пересчёт внимания
Вместо того чтобы хранить все промежуточные значения, FlashAttention пересчитывает некоторые из них на лету.
Это увеличивает вычислительную нагрузку, но значительно снижает потребление памяти.
В результате для последовательности из 100K токенов FlashAttention может использовать в 10 раз меньше памяти, чем стандартное внимание.
Сравнение с обычным вниманием

Обычное внимание требует O(n²) памяти для матрицы внимания. FlashAttention требует O(n) памяти, так как хранит только текущий блок. Скорость также выше за счёт эффективного использования кэша GPU.
Другие методы оптимизации
Помимо FlashAttention, Claude может использовать:
- Параллельная обработка сегментов: Разбиение длинного текста на сегменты, которые обрабатываются параллельно на разных GPU, с последующей агрегацией результатов.
- Использование GPU с большим объёмом памяти: Anthropic, вероятно, использует специализированные кластеры с GPU, такими как A100 или H100, которые имеют до 80 ГБ VRAM.
Ограничения и компромиссы при обработке длинных текстов
Даже с продвинутыми техниками, обработка длинных контекстов остаётся сложной задачей с компромиссами.
Важно понимать эти ограничения, чтобы правильно использовать модель.
Потеря информации на больших расстояниях
Модель может терять детали из начала контекста при очень длинных последовательностях.
Это связано с тем, что разреженное внимание и рекуррентные блоки не могут идеально сохранять всю информацию.
Эффект ‘забывания’
Исследования показывают, что даже с окном внимания в 4096 токенов, модель хуже отвечает на вопросы, требующие информации из начала текста.
Для Claude это проявляется в снижении точности на контекстах длиной более 50K токенов.
Влияние на качество ответов
На практике это означает, что при работе с очень длинными документами (например, книгами) Claude может упустить важные детали.
Рекомендуется разбивать текст на логические части и задавать вопросы по каждой части отдельно.
«Даже с продвинутыми техниками, обработка длинных контекстов остается сложной задачей с компромиссами. Понимание этих ограничений помогает правильно формулировать запросы и ожидания».
Вычислительная стоимость
Хотя оптимизации снижают затраты, обработка длинных текстов всё равно требует значительных ресурсов.
Время инференса
Для контекста в 100K токенов время генерации первого токена (prefill) может составлять несколько секунд, даже с FlashAttention. Это важно учитывать в real-time приложениях.
Потребление VRAM
Даже со сжатием KV cache, для контекста в 200K токенов может потребоваться более 80 ГБ VRAM. Это ограничивает использование Claude на обычных GPU.
Сравнение Claude с другими моделями по работе с длинными текстами
Claude выделяется не только длиной контекста, но и эффективностью его использования. Сравним его с основными конкурентами.
Сравнительная таблица характеристик

| Модель | Максимальная длина контекста | Метод внимания | Эффективность | Качество на длинных текстах |
|---|---|---|---|---|
| Claude 3 Opus | 200K токенов | Разреженное + скользящее окно | Высокая | Отличное |
| GPT-4 Turbo | 128K токенов | Разреженное (предположительно) | Средняя | Хорошее |
| Gemini 1.5 Pro | 1M токенов | MoE + разреженное | Очень высокая | Хорошее (с оговорками) |
| Llama 3 70B | 8K токенов (стандарт) | Полное внимание | Низкая для длинных контекстов | Отличное для коротких текстов |
Ключевые выводы из сравнения
Claude 3 Opus предлагает хороший баланс между длиной контекста и качеством. Gemini 1.5 Pro может обрабатывать до 1M токенов, но на практике качество на таких длинах может снижаться.
GPT-4 Turbo уступает по длине, но показывает стабильные результаты. Llama 3, хотя и не предназначена для длинных контекстов, остаётся сильным игроком в своей нише.
Сильные стороны Claude
- Стабильное качество на контекстах до 200K токенов.
- Эффективное использование памяти благодаря комбинации техник.
- Хорошая интеграция с рекуррентными блоками для сохранения долгосрочных зависимостей.
Слабые стороны
- Уступает Gemini по максимальной длине контекста.
- Может терять детали на очень больших расстояниях (более 50K токенов).
Частая ошибка: Сравнивать модели только по длине контекста. Важно учитывать, как модель использует этот контекст — некоторые модели просто «забывают» информацию из начала.
Практические советы по использованию Claude для длинных текстов
Правильная формулировка запроса может значительно улучшить качество ответа при работе с длинными контекстами. Вот несколько рекомендаций.
Структурирование входного текста

Разбивайте длинный текст на логические части с помощью заголовков и маркеров. Это помогает модели лучше понимать структуру.
- Использование разделителей: Вставляйте маркеры вроде ===РАЗДЕЛ 1=== или [ГЛАВА 2] между частями текста.
- Явное указание важных частей: В начале запроса напишите: «Обрати особое внимание на раздел 3 и 5».
Формулировка запросов для длинных контекстов
Чтобы модель фокусировалась на нужных частях, используйте уточняющие вопросы.
- Уточнение релевантности: Вместо «Что сказано в тексте?» спросите «Какие аргументы приведены в поддержку тезиса X на страницах 10-15?».
- Запросы с указанием позиции: «Найди информацию о Y в начале документа» или «Что говорится о Z в последних абзацах?».
Если вы автоматизируете тестирование с помощью плагинов и CI/CD-интеграций, вы можете интегрировать Claude в свой пайплайн для анализа длинных логов или документации — это значительно ускорит процесс.
Совет: При работе с очень длинными текстами (более 100K токенов) попробуйте сначала попросить Claude сделать краткое изложение каждой части, а затем задать вопрос по всему тексту.
Часто задаваемые вопросы
Какова максимальная длина контекста в Claude?
Claude 3 Opus поддерживает контекст до 200 000 токенов.
Это позволяет обрабатывать тексты объёмом около 150 000 слов, что соответствует примерно 300 страницам книги.
Почему Claude не может обрабатывать контексты длиной в 1 миллион токенов, как Gemini?
Каждая модель имеет свои компромиссы. Gemini использует архитектуру Mixture of Experts и другие оптимизации, которые позволяют ему работать с миллионом токенов, но это может сказываться на качестве для некоторых задач.
Claude фокусируется на стабильности и точности в пределах 200K токенов.
Влияет ли длина контекста на скорость ответа?

Да, чем длиннее контекст, тем больше времени требуется на обработку. Для контекста в 200K токенов время первого токена может составлять несколько секунд.
Однако последующая генерация токенов происходит быстро благодаря KV cache.
Может ли Claude обрабатывать текст, превышающий его контекстное окно?
Нет, если текст превышает максимальную длину, модель не сможет его обработать целиком.
В таких случаях рекомендуется разбить текст на части и обрабатывать их последовательно или параллельно.
Какие типы задач лучше всего подходят для длинных контекстов Claude?
Claude отлично справляется с анализом документов, суммаризацией длинных текстов, извлечением информации, ответами на вопросы по большим объёмам данных и поддержкой длительных диалогов.